Microservices For Greenfield?
Posted on Apr 7 2015
I was having a chat with a colleague recently about the project (codename: Asterix) that they were working on. She was facing the question: Do we start monolithic, or start with microservices from the beginning of a greenfield project? While I do cover this off in a few places in the book, I thought it might be worth sharing the trade-offs we discussed and the conclusion we came up with to give you a sense of the sorts of things I consider when people ask me if they should use microservices. Hopefully this post will be a bit more informative than me just saying "It depends!".
Knowing The Domain
Getting service boundaries wrong can be expensive. It can lead to a larger number of cross-service changes, overly coupled components, and in general could be worse than just having a single monolithic system. In the book I shared the experiences of the SnapCI product team. Despite knowing the domain of continuous integration really well, their initial stab at coming up with service boundaries for their hosted-CI solution wasn't quite right. This led to a high cost of change and high cost of ownership. After several months fighting this problem, the team decided to merge the services back into one big application. Later on, when the feature-set of the application had stabilized somewhat and the team had a firmer understanding of the domain, it was easier to find those stable boundaries.
In the case of my colleague on the Asterix project, she is involved in a partial reimplementation of an existing system which has been around for many years. Just because a system has been around for a long period of time, doesn't mean the team looking after it understands the key concepts in it. This particular system makes heavy use of business rules, and has grown over time. It definitely works right now, but the team working on the re-platforming are new enough to the domain that identifying stable boundaries is likely to be problematic. Also, it is only a thin sliver of functionality that is being reimplemented to help the company target new customers. This can have a drastic impact on where the service boundaries sit - a design and domain model that works for the more complex existing system may be completely unsuited to a related but different set of use cases targeted at a new market.
At this point, the newness of the domain to the team leads me strongly towards keeping the majority of the code in a single runtime, especially given the changes that are likely to emerge as more research is done into the new potential customers. But that's only part of the story.
Deployment Model

The existing platform is a system which is deployed at multiple customer locations. Each customer runs their own client-server setup, and is responsible for procuring hardware for the deployment, and has some responsibility for installing the software (or for outsourcing this to another party). This type of model fits quite badly for a microservice architecture.
One of the ways in which we handle the complexity of deploying multiple separate services for a single install is by providing abstraction layers in the form of scripts, or perhaps even declarative environment provisioning systems like Terraform. But in these scenarios, we control many variables. We can pick a base operating system. We run the install ourselves. We can (hopefully) control access to the machines we deploy on to ensure that conflicts or breaking changes are kept to a minimum. But for software we expect our customers to install, we typically control far fewer variables.
We also ideally we want a model where each microservice is installed in it's own unit of operating system isolation. So do our customers now need to buy more servers to install our software?
A couple of people at microxchg in Berlin asked me about this challenge, and I told them that until we see more commonly-available abstraction layers over core infrastructure (mesos, Docker, or internal PAAS solutions etc) that can reduce the cost of end-user installs of microservice-based systems, that this was always going to be a fraught activity. If you are operating in such an environment I would generally err towards again keeping the system more monolithic.

Many vendors in this space look for module-based systems to provide the ability to hot-deploy new components as opposed to requiring multiple independent processes. Some of these module systems are better than others. I worked with a team on a content system based heavily on DayCQ (now part of Adobe Experience Manager) which made use of OSGI. One of the promises of OSGI is that you can download new modules or upgrade existing modules without having to restart the core system. In reality, we found this isn't always the case. Frequently it would be non-obvious what sort of module changes would require a restart, and much of the burden fell to module authors to ensure that this hot-deployment capability was retained. We felt that much of this was due to the problems associated with trying to shoehorn a module system into a platform that doesn't support it by way of a library. I really hope Java 9's Jigsaw module system will change things here.
Luckily for my colleague, one of the driving reasons behind them building a new version of the existing system is to roll out a multi-tenant, SAAS product, removing the need for customers to have to install and manage their own software. In fact, the client is open to the idea of deploying on to a public cloud provider like AWS, which has additional benefits as these platforms offer significant support in the form of APIs to help provision and configure our infrastructure. The one wrinkle in the case of the Asterix project is that there are some regulatory requirements about how data can be handled which may limit how readily we could use a public cloud. The team is investigating these requirements, but for the moment is working under the assumption that this will be hosted on a cloud provider somewhere, either public or private. Assuming this remains the case, it doesn't seem like constraints on our deployment model are going to be a barrier to using microservices.
Technology
Multiple service boundaries allow you to use different technologies for different problems, giving you more chance to bring the right tool to bear to solve a particular solution. It also allows us to adapt to constraints that might exist in our problem space. One aspect of the Asterix project is the fact that there are significant integration requirements with a third party. This third party provides both C and Java libraries, and using the provided client libraries is a fairly hard requirement due to the complexity of interaction with the underlying service provider. If we were adopting a single, monolithic runtime, we'd then either need to use a stack that can integrate with the C library, or a Java platform where we could just use the Java library. Much of the rest of the system though really fits a simple web application structure, for which the team would lean towards a Ruby-based solution, using something like Rails or Sinatra.
The third-party handles sensitive data, and it is important this gets where it is going. In the current customer-installed, single tenancy system, when the third-party integration fails, it is obvious to the operator, the impact is clear, and they can just try again later. With a multi-tenancy approach, any outage or problem with this integration could have wide-reaching impact, as a single component outage could affect multiple customers.
The importance of this integration point, and the asynchronous nature of the comms with the 3rd party, meant that we may have to try some different things in terms of resiliency and architecture. By making this a service in its own right we'd be opening up some more possibilities in how we handle things.
The nature of the integration point itself also is a very clear boundary for us, one that is also unlikely to change given how stable it is for the existing product. This was what led my colleague to think of keeping this component as a separate, Java-based service. The rest of the standard web stack would then communicate with this service. This would allow us to handle resiliency of service to the third party within this stable unit, keeping the rest of the faster-moving technology stack in Ruby-land.
Ownership
As a consultancy, we have to handle the fact that the systems we build will need to be handed over and owned by the client in the long term. Although the clients existing system has been around for a fairly long time, their experience is in the design, development and support for a customer-installed client-server application, not a multi-tenancy cloud-based application. Throwing a fine-grained architecture into the mix from the off felt like a step too far for us. While working with the client we'll continue to assess their ability to take on this new technology and new ways of thinking, and although they are very keen it should still be a phased approach.
Another mark against going too fine-grained, at least at the beginning.
Security
This particular application has very sensitive data in it. We talked about some models that could protect it, including pulling out the especially sensitive data so that could be stored on a per-customer basis (e.g. single tenant one part of the application stack) or at the very least have it stored somewhere with encryption at rest. The industry this application is used in is highly regulated, and right now it is unclear what all the requirements are. The team plan to go and investigate what the regulator needs. It may well be that by decomposing the application earlier that we reduce the scope of the system that needs to be audited which may be a significant bonus.
Right now though these requirements weren't clear, so it felt premature to decide on a service boundary which would manage this data. Investigating this further remains a high priority though.
A Monolith, Only Modular
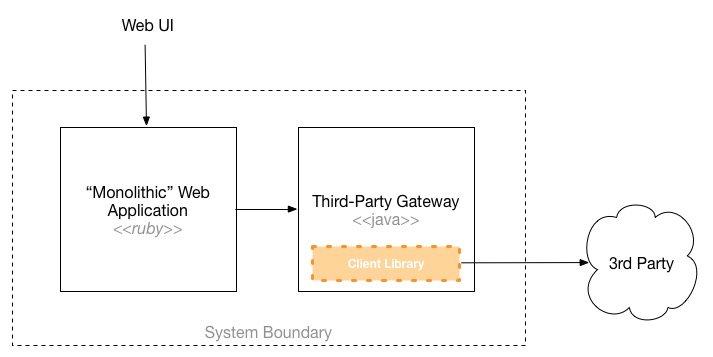
In the end it turns out that my colleague had already come up with the same thinking I did. Given what they currently know, the team is keeping the core system as a 'mostly monolithic' Ruby application, with a separate Java service to handle integration to the third-party integration point.
The team are going to look at is how to make it easy to split the ruby application at a later date. When deciding later on to make an in-process module a separate microservice, you face two challenges. The first is separating the code cleanly, and creating a coarse-grained API that makes sense to be used over a network rather than the fine-grained method calls we may permit inside a single process. The other challenge though is pulling apart any shared persistent data storage to ensure our two newly separated services don't integrate on the same database. This last point is typically the biggest stumbling block.
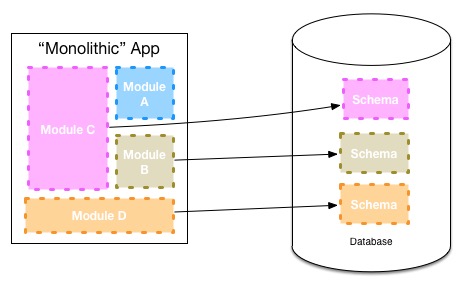
To deal with this, one of our internal development teams inside ThoughWorks decided that it made sense to map modules which they felt could at some point in the future become services in their own right to their own data schemas, as seen above. This obviously has a cost. But by paying this cost they kept their options open - pulling the service apart at a later date becomes easier as a result. The Asterix team are going to consider using the same approach within their ruby application.
The Asterix team will need to keep a close eye on the module boundaries within the main application code base. In my experience it is easy for what starts off as clear modular boundaries to become so intermingled that future decomposition into services is very costly. But by keeping the data models completely separate in the application tier and avoiding referential integrity in the database, then separation further down the line shouldn't be hugely challenging.
Better Brownfield?
I remain convinced that it is much easier to partition an existing, "brownfield" system than to do so up front with a new, greenfield system. You have more to work with. You have code you can examine, you can speak to people who use and maintain the system. You also know what 'good' looks like - you have a working system to change, making it easier for you to know when you may have got something wrong or been too aggressive in your decision making process.
You also have a system that is actually running. You understand how it operates, how it behaves in production. Decomposition into microservices can cause some nasty performance issues for example, but with a brownfield system you have a chance to establish a healthy baseline before making potentially performance-impacting changes.
I'm certainly not saying 'never do microservices for greenfield', but I am saying that the factors above lead me to conclude that you should be cautious. Only split around those boundaries that are very clear at the beginning, and keep the rest on the more monolithic side. This will also give you time to assess how how mature you are from an operational point of view - if you struggle to manage two services, managing 10 is going to be difficult.
It should be noted that this blog post outlines a discussion at a single point in time. As the Asterix team learn more, and the direction of the product they are creating changes, my colleague and her team may well find themselves having to change direction again. Architectural decisions like this are not set in stone - we just make the best call we can at the time. Having some framing for the decision making process though, as I have outlined above, gives you some mental models to use when assessing 'so what do we do now?'. It'll be fun to see where Project Asterix ends up - I may well blog about it again in the near future.
Back to Blog.